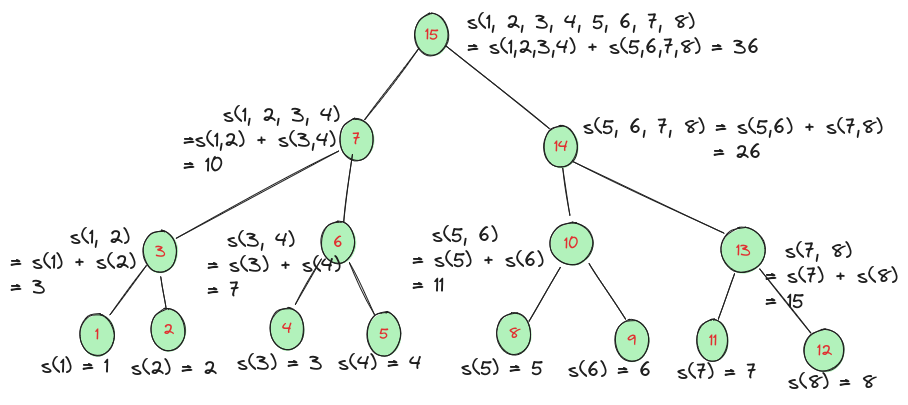
Die Nummerierung der Knoten entspricht der Berechnungsreihenfolge.
2 Array Zerlegung
Eine nicht-konstante Laufzeit ensteht, falls uebergebene arrays auf den Stack des Funktionsaufrufs kopiert werden muessen.
Wenn eine gegebene Implementierung der Programmiersprache folgende zwei Eigenschaften aufweist, kann dies vermieden werden:
Die Groesse eines Arrays ist immer als zusaetzliche Information beinhaltet.
Die Funktionsaufrufe werden per-default als call by reference realisiert statt call by value.
So wuerde fuer einen existierenden Array \(A : \text{Array} [0 .. n - 1] \text{ of } \mathbb{N}\) der allgeimeiner Ausdruck \(A[l..k]\) einen Array liefern, dessen Anfang-position im Speicher und Groesse durch Pointerarithmetik, bzw durch den Ausdruck \(k - l + 1\) bestimmt werden koennen. Das sind nur zwei Grundoperationen, und somit \(\mathcal{O}(1)\)
Da die Uebergabe der Arrays per Referenz stattfindet, wuerden die Aufrufe sum(A[0..m-1]) und sum(A[m..n-1]) nur konstante Zeit bei der Initialisuerungen auf ihren Function call-stacks benoetigen.
Da, die Eingabe bei jedem Aufruf halbiert wird ist die Tiefe des Rekurrenzbaums (Figure 2.1) \(k = \log_2(n)\). Dieser Baum ist vollstaendig binaer, deshalb enthaelt jede Tiefe \(i\) genau \(2^i\) Knoten, fuer \(i=0\dots k\). Somit betreagt die Gesamtzahl der Knoten:
Bei jedem Knoten wird eine konstante Anzahl von Additions- & Zuweisungsoperationen durchgefuehrt, und das Ergebnis zur aufrufenden Funktion zurueckgegeben. Somit ist die Laufzeit proportional zur Anzahl der Knoten, die wir in der vorangehenden Diskussion berechnet haben, d.h. \(T(n) = c_1n + c_2\). Dann gilt offensichtlich \(T(n) = \Theta(n)\)
4 Laufzeit Parallel
Da, der zweite rekursive Aufruf bereits berechnet ist zum Zeitpunkt der erste Fertig ist, muss sein Zeitaufwand nicht zuesaetzlich addiert werden. Somit erfuellt fuer diesen Fall die Laufzeit folgende Rekurrenzgleichung:
Der Ausdruck \(C(n/4) + n + 6\) kann asymptotisch als \(C(n/4) + n\) kann vereinfacht werden, da Addition mit konstante vernachlaessigt werden kann. Somit:
\[\begin{align*}
& a = 1, \\
&c = 1, \\
&d = 1 < 4 = b \\
\Rightarrow &T(n) \in \Theta(n) \tag{Fall $d < b$ des MT}
\end{align*}\]
d)
In c) wurde gezeigt, dass \(C(n) \in \Theta(n)\). Somit kann \(C(n)\) fuer asymptotische Zwecke durch \(c\cdot n\) erzetzt werden. Dann gilt:
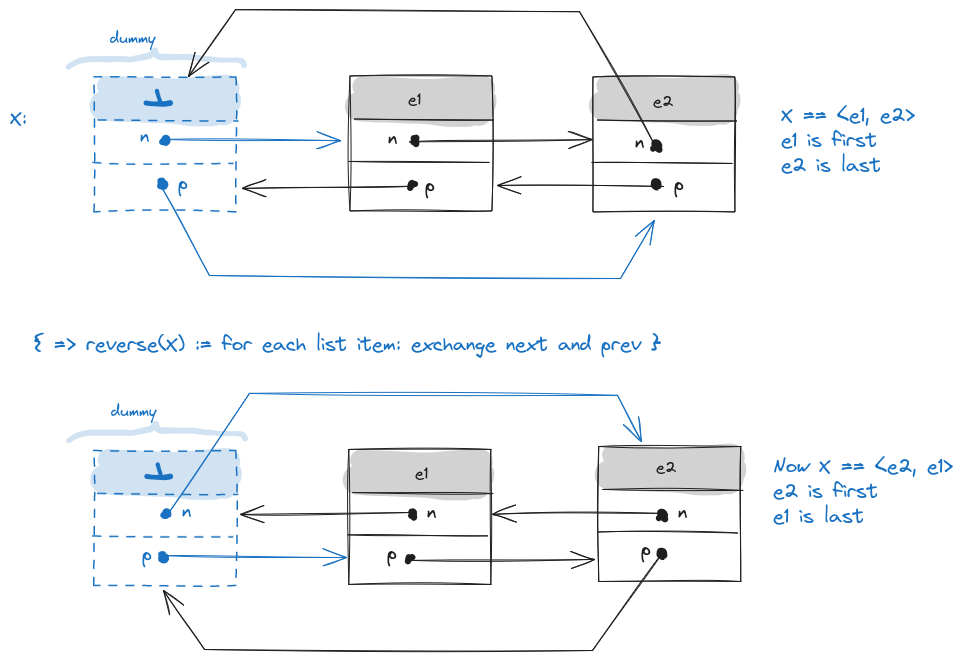
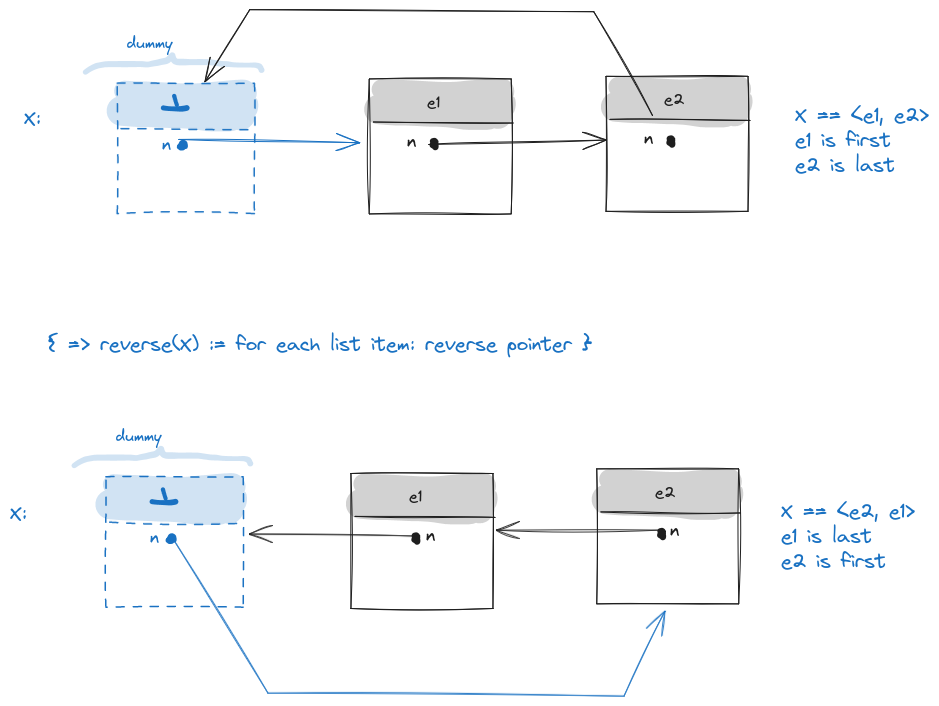
Wir gehen von einer Implementierung aus, die das Dummy-element verwendent, wie in der VL beschrieben.
Idee: Tausche fuer jedes List-Item die Pointer next und prev aus. Illustration:
Reverse DLList
Pseudocode implementierung:
procedure reverse(X : List<T>) assert(not X.is_empty()) // let initially X == <e1, ..., e_n> // exchange dummy's prev and next pointers ip := X.first() : *Item<T> X.first() := X.last() X.last() := ip // invariant: reversed from e1 up-to (excluding) *ip while (ip->next != &dummy) //exchange next and prev of the item pointed by ip ip_next := ip->next : *Item<T> ip->next := ip->prev ip->prev := ip_next ip = ip_next //increment to next item //post-loop: *ip == e_n // take care of e_n's pointers: ip.next = ip.prev ip.prev = &dummy
Siehe Kommentare fuer den Beweis der Korrektheit
Der Algorithmus benoetigt keine zusaetzliche Worte, da es keine neue Listenelemente abgelegt oder existierende Elemente kopiert werden. Es werden einfach nur Pointer ausgetauscht.
Die Listenelemente werden sequentiell durchgelaufen und fuer jedes Element werden eine konstante Anzahl von Grundoperationen durchgefuehrt \(\Rightarrow \mathcal{O}(n)\).
2 Array
Idee: Tausche die ‘aussersten’ noch nicht ausgetauschten Elementen aus, und inkrementiere zu den inneren. Siehe das Bild:
Reverse Array
Pseudocode:
procedure reverse(X: Array[0..n-1] of Nat) i := 0 : Nat // invariant: the X[0..i-1] and X[(n-1) - (i-1) .. n-1] // portions of X are reversed while (i < n/2) temp := X[i] : Nat X[i] := X[(n-1) - i] X[(n-1) - i] := temp i := i + 1 //post-loop: i == ceiling(n/2)
Python Beispiel:
def reverse(X) : i =0 n =len(X)while (i < n/2) : temp = X[i] X[i] = X[(n-1) - i] X[(n-1) - i] = temp i = i +1return XX = [1, 2, 3, 4]Y = [1, 2, 3, 4, 5]Z = [1, 2, 3, 4, 5, 6]print(reverse(X))print(reverse(Y))print(reverse(Z))
[4, 3, 2, 1]
[5, 4, 3, 2, 1]
[6, 5, 4, 3, 2, 1]
Siehe die Kommentare im Pseudocode fuer den Beweis der Korrektheit
Der Algorithmus verwendet keine neue Worte, da die Eintrage des Arrays “in-place” ausgetauscht werden. D.h. der vorhandene Array wird ueberschrieben
Der Algorithmus besteht aus einer while-schleife mit \(n/2\) iterationen \(\Rightarrow \Theta(n)\).
3 Simply Linked List
Idee: Gehe die Liste durch und drehe die Pointer fuer jedes Listenelement um. Siehe das Bild:
Reverse SList
Pseudocode:
reverse(X : SList<T>) assert(not X.is_empty()) // let <e1,...,e_n> be the initial contents of the list // i.e. initially X == <e1,...,e_n> ip := X.first() : *Item<T> //*ip == e1 ip_next := ip->next : *Item<T> //*ip_next == e2 ip->next := &dummy //e1 is now last //invariant: // (*ip == e_k) => // *ip_next == e_(k+1)) // && //reversed from e1 to e_k, i.e. X == <..TBD..,e_k, ..., e1> while (ip_next != &dummy) ip_next_next := ip_next->next : *Item<T> ip_next->next := ip ip := ip_next ip_next := ip_next_next //post-loop: *ip == e_n // take care of dummy's next pointer X.first() := ip
Siehe Kommentare im Pseudocode
Nur Pointer werden ueberschrieben \(\Rightarrow\) keine extra Speicherbelegung.
Sequentielle Bearbeitung der Listenelemente \(\Rightarrow \Theta(n)\)
4 Fast Reverse
Das ist nicht moeglich, da Kopieren einer Liste oder eines Arrays der Laenge \(n\)\(\Theta(n)\) Operationen benoetigen wuerde. Somit sind Algorithmen, die Listen- oder Arrayelemente kopieren mindestens \(\Theta(n)\). Unsere “in-place” Algorithmen sind bereits \(\Theta(n)\)